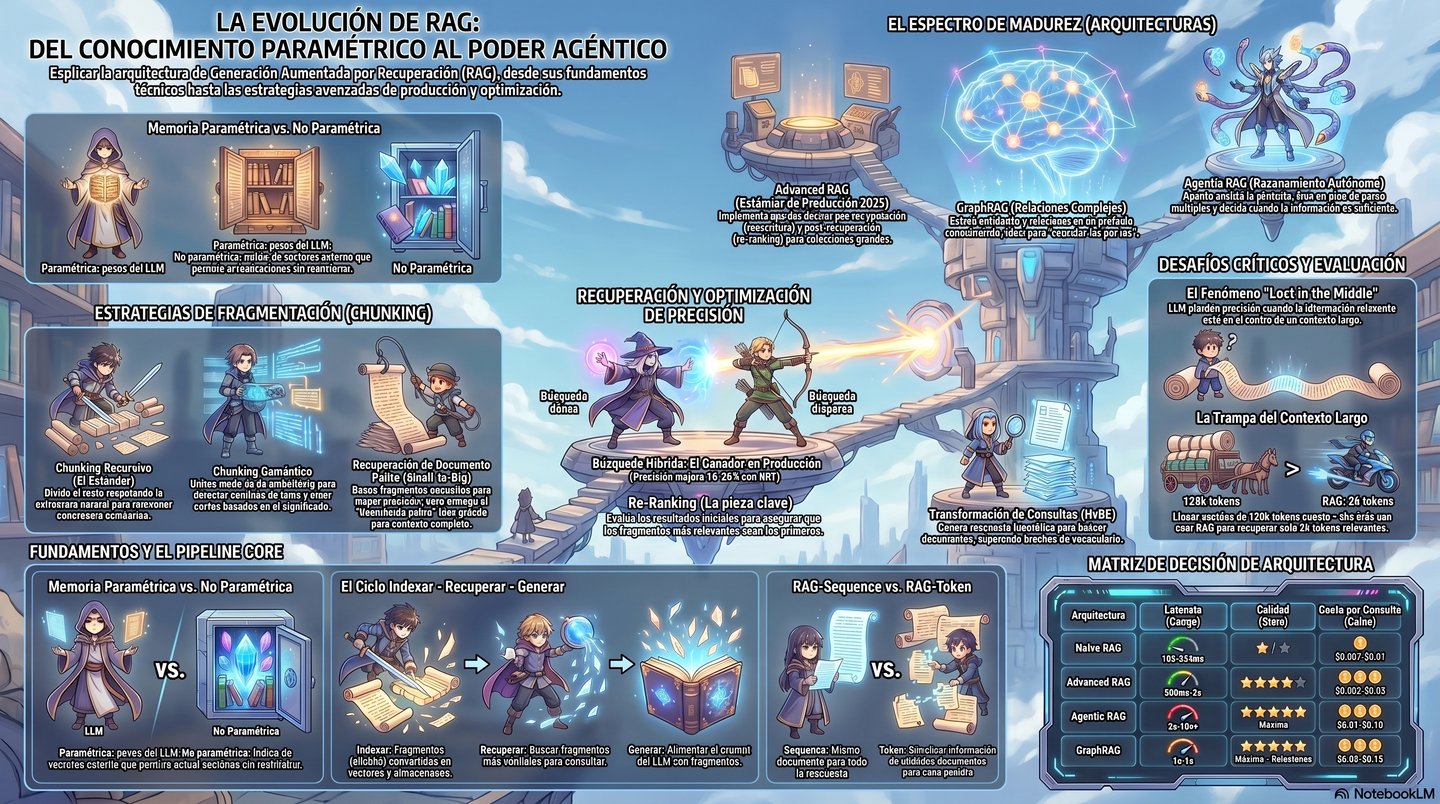
Arquitecturas Avanzadas de Generación Aumentada por Recuperación (RAG) en el Dominio Jurídico
Un Análisis Integral de la Soberanía de Datos, la Precisión Semántica y el Estado del Arte en LegalTech
IA Y DERECHO
5/9/202619 min read
La integración de la inteligencia artificial generativa en el ámbito del derecho ha transitado rápidamente de la experimentación teórica a una necesidad operativa crítica. Sin embargo, el despliegue de modelos de lenguaje de gran tamaño (LLM) en entornos jurídicos se enfrenta a desafíos fundamentales: la tendencia a la alucinación, la falta de actualización de los datos de entrenamiento y la opacidad en la trazabilidad de las fuentes. La arquitectura de Generación Aumentada por Recuperación (RAG) ha emergido como la solución técnica predominante para mitigar estos riesgos, permitiendo que los modelos no solo generen texto, sino que fundamenten sus respuestas en un corpus documental verificado y dinámico.1 En esta investigación se analiza exhaustivamente la evolución del pipeline RAG aplicado a documentos de alta complejidad estructural, como demandas, sentencias y contratos, examinando desde las estrategias de segmentación de texto hasta las métricas de evaluación que garantizan la fiabilidad exigida por la práctica profesional del derecho.
Fundamentos Teóricos del Pipeline RAG en el Contexto Jurídico
El sistema RAG no debe entenderse como un componente estático, sino como un ecosistema modular de procesos interconectados que transforman una consulta en lenguaje natural en una respuesta legalmente vinculada. A diferencia de los modelos paramétricos tradicionales, RAG separa la capacidad de razonamiento del LLM de su base de conocimientos, utilizando el modelo únicamente como un procesador de contexto extraído en tiempo real de fuentes externas.4 El flujo de trabajo estándar se divide en dos fases principales: la fase de ingesta (indexación) y la fase de consulta (recuperación y generación).7
En la fase de indexación, el conocimiento jurídico se descompone en unidades atómicas para ser almacenado en una base de datos vectorial. Este proceso es crítico porque la calidad de la recuperación posterior depende directamente de cómo se haya estructurado la información inicial. En el derecho, donde el significado a menudo reside en la relación jerárquica entre normas, una indexación plana suele ser insuficiente.3 La fase de consulta comienza cuando un profesional formula una pregunta. El sistema convierte esta consulta en un vector numérico, busca los fragmentos más relevantes en el almacén de vectores y presenta estos fragmentos al modelo de lenguaje junto con la pregunta original.2 El resultado es una respuesta que, idealmente, incluye citas directas a las leyes o jurisprudencia consultadas, permitiendo al abogado verificar la veracidad de la salida.9
El Papel Crítico de la Recuperación de Información (IR)
La literatura académica reciente sostiene que la recuperación de información es el verdadero motor del rendimiento en los sistemas RAG jurídicos, incluso por encima de la capacidad de razonamiento del LLM utilizado.11 Un modelo de lenguaje extremadamente potente no puede compensar una recuperación fallida; si el sistema no localiza el artículo exacto de la ley o la sentencia vinculante, la generación resultante será, en el mejor de los casos, genérica y, en el peor, una alucinación peligrosa.13 En el dominio legal, la recuperación se enfrenta a la "redundancia léxica", donde múltiples documentos comparten términos idénticos pero con aplicaciones jurídicas radicalmente distintas.3 Por ello, las arquitecturas modernas han evolucionado hacia la "recuperación híbrida", que combina la búsqueda por similitud vectorial (semántica) con la búsqueda por palabras clave tradicional (lexical), como el algoritmo BM25.2
Componente del Pipeline
Función en el Dominio Legal
Impacto en la Calidad
Ingesta de Documentos
Extracción de texto y estructura de PDFs y sentencias.
Determina la fidelidad de la base de conocimientos.
Chunking
División de documentos en fragmentos manejables.
Evita la pérdida de contexto en cláusulas largas.
Embedding
Conversión de texto en vectores matemáticos.
Captura matices entre términos legales similares.
Búsqueda Vectorial
Identificación de fragmentos por similitud semántica.
Proporciona el contexto necesario para la respuesta.
Reranking
Reordenación de fragmentos por relevancia exacta.
Filtra ruidos y mejora la precisión final.
Generación (LLM)
Síntesis de la respuesta con citas y razonamiento.
Produce la salida final legible y estructurada.
Estrategias de Chunking para Documentos Jurídicos de Estructura Variable
El chunking o segmentación es el proceso de dividir un documento largo en piezas más pequeñas para que quepan en la ventana de contexto de los modelos de embedding y generación. En el derecho, esta tarea es especialmente compleja debido a que los documentos (demandas, contratos, reglamentos) poseen una estructura lógica y jerárquica que es esencial para su interpretación.3 Un corte arbitrario en medio de una cláusula de limitación de responsabilidad podría hacer que el sistema recupere solo la excepción y no la regla general, llevando a conclusiones erróneas.15
Segmentación por Tamaño Fijo frente a Segmentación Estructural
El método más básico es el chunking de tamaño fijo, que corta el texto cada determinado número de tokens o caracteres, usualmente con un solapamiento para mitigar la pérdida de información en los bordes.16 Aunque es eficiente computacionalmente, este enfoque es propenso a romper la cohesión semántica de los textos legales. Para documentos de estructura variable, se han desarrollado estrategias más sofisticadas:
Recursive Character Splitting: Este método intenta dividir el texto siguiendo una jerarquía de separadores naturales del lenguaje legal: primero por artículos o secciones, luego por párrafos, luego por oraciones y, finalmente, por palabras si el fragmento sigue siendo demasiado grande.15 Esto asegura que, en la mayoría de los casos, un artículo completo se mantenga como una unidad coherente.
Document-Based / Structure-Aware Chunking: En contratos y estatutos, esta estrategia utiliza la estructura de metadatos del documento para realizar cortes. Cada cláusula se convierte en un fragmento independiente. Si una cláusula es muy extensa, se subdivide respetando los apartados numéricos.16
Semantic Chunking: Utiliza modelos de IA para detectar cambios de tema dentro de un texto. En una sentencia judicial de 50 páginas, el sistema identifica dónde termina la exposición de hechos y dónde comienza la fundamentación jurídica, creando fragmentos basados en la transición temática más que en la longitud del texto.2
Innovaciones en Contexto Global: Summary-Augmented Chunking (SAC)
Una de las limitaciones críticas del chunking tradicional es la pérdida de la "visión de conjunto". Un fragmento de una cláusula contractual puede parecer relevante aisladamente, pero su significado real puede depender de una definición establecida cien páginas atrás. Para solucionar esto, técnicas como el Summary-Augmented Chunking (SAC) proponen generar un resumen del documento completo y añadirlo como prefijo a cada fragmento individual antes de la indexación.3 Esto dota a cada vector de una "huella digital" del contexto global del documento, reduciendo drásticamente el Document-Level Retrieval Mismatch (DRM), una falla común donde el sistema recupera fragmentos de documentos incorrectos que simplemente comparten lenguaje de plantilla (boilerplate).3
Estrategia de Chunking
Aplicación Recomendada
Ventajas Jurídicas
Tamaño Fijo con Solapamiento
Prototipos rápidos, textos narrativos simples.
Simplicidad de implementación.
Segmentación por Cláusulas
Contratos, pólizas de seguros, términos y condiciones.
Mantiene la integridad de las obligaciones legales.
LegRAG (Ruta Dual)
Jurisprudencia, legislación codificada.
Procesa párrafos y artículos en paralelo para máxima precisión.20
SAC (Aumentado por Resumen)
Corpus grandes con documentos muy similares entre sí.
Inyecta contexto global en fragmentos locales.8
IdeaBlocks (Pre-procesamiento)
Auditorías legales masivas, due diligence.
Elimina redundancias y fragmenta en unidades de concepto únicas.21
Modelos de Embedding y el Espacio Semántico Legal
El embedding es el proceso de transformar el texto en una representación vectorial en un espacio multidimensional donde la distancia entre dos puntos refleja su similitud de significado. Los modelos de embedding de propósito general, aunque potentes, a menudo no logran distinguir matices técnicos que son vitales en el derecho, como la diferencia entre "arrendamiento" y "usufructo", que en un espacio vectorial genérico podrían aparecer como sinónimos cercanos pero que tienen implicaciones legales divergentes.2
La Revolución de los Modelos Especializados: Kanon 2 y MLEB
En 2025, el panorama de los embeddings ha sido transformado por modelos adaptados al dominio legal. El modelo Kanon 2 Embedder ha demostrado superar sistemáticamente a gigantes como OpenAI y Google en el Massive Legal Embedding Benchmark (MLEB), un conjunto de datos diseñado para evaluar la recuperación en casos, legislación, regulaciones y contratos.22 Estos modelos son entrenados mediante "aprendizaje por contraste" en corpus masivos de documentos jurídicos, permitiéndoles mapear consultas en lenguaje natural de clientes hacia la terminología técnica precisa de las fuentes primarias.22
Una innovación técnica destacada en estos modelos es el uso de Embeddings Matryoshka. Esta técnica permite que un vector de alta dimensión (por ejemplo, 1,792 dimensiones) sea truncado a tamaños mucho menores (como 256 dimensiones) sin una pérdida catastrófica de precisión.22 Para las firmas legales que gestionan millones de documentos, esto reduce los costos de almacenamiento y aumenta la velocidad de búsqueda en órdenes de magnitud, facilitando despliegues en hardware más modesto o en la nube con menor latencia.23
Gestión de Metadatos y Filtrado Estructurado
La búsqueda vectorial pura puede ser imprecisa cuando la relevancia de un documento depende de criterios extrínsecos, como la jurisdicción, la fecha de vigencia o el tribunal emisor. Por ello, un diseño de esquema de metadatos robusto es obligatorio en cualquier RAG jurídico profesional.4 El filtrado por metadatos actúa como un paso de "pre-filtrado" o "post-filtrado" que restringe el espacio de búsqueda vectorial a solo aquellos documentos que cumplen con los requisitos legales específicos del caso.27
Categoría de Metadato
Ejemplo de Campo
Importancia Jurídica
Temporal
fecha_sentencia, vigencia_norma
Evita citar leyes derogadas o jurisprudencia obsoleta.
Jurisdiccional
tribunal, comunidad_autonoma, pais
Asegura que la fuente sea aplicable al foro del caso.
Jerárquico
tipo_norma (Ley Orgánica vs. Decreto)
Permite aplicar el principio de jerarquía normativa en el razonamiento.
Identificativo
id_cliente, num_expediente, privilegio
Crucial para la seguridad y el cumplimiento ético (secreto profesional).28
Técnicas Avanzadas de Recuperación: HyDE, RAG-Fusion y Reranking
Incluso con los mejores embeddings, la brecha lingüística entre cómo un usuario formula una pregunta y cómo está escrita la ley puede degradar la recuperación. Las técnicas avanzadas de recuperación buscan cerrar esta brecha transformando la consulta o procesando los resultados de manera iterativa.2
HyDE: Hypothetical Document Embeddings
La técnica HyDE propone una solución ingeniosa a la disparidad entre consulta y documento. En lugar de buscar directamente con la pregunta del usuario, el sistema le pide a un LLM que genere una respuesta hipotética. Aunque esta respuesta pueda contener datos falsos, utilizará el "lenguaje de respuesta" típico del dominio legal.4 El sistema luego vectoriza esta respuesta hipotética y la utiliza para buscar en la base de datos. Esta aproximación de "respuesta a respuesta" es mucho más efectiva para localizar documentos técnicos que la búsqueda tradicional de "pregunta a respuesta".29 Por ejemplo, si un usuario pregunta "¿qué pasa si mi socio no me paga?", HyDE genera un texto sobre "incumplimiento de aportaciones sociales", logrando una coincidencia semántica mucho más alta con el Código de Comercio.30
RAG-Fusion y la Diversidad de Consultas
RAG-Fusion mejora la recuperación generando múltiples variaciones de la consulta original desde diferentes perspectivas. Para una consulta sobre "despido improcedente", el sistema podría generar variaciones enfocadas en "indemnización por despido", "causas objetivas de extinción" y "jurisprudencia del Tribunal Supremo sobre despidos".14 Cada una de estas consultas se ejecuta de forma independiente, y los resultados se fusionan utilizando Reciprocal Rank Fusion (RRF). Este algoritmo otorga una puntuación más alta a los documentos que aparecen consistentemente en los primeros lugares de las diferentes búsquedas, lo que proporciona una robustez estadística superior frente a consultas ambiguas o mal formuladas.14
La Capa de Reranking: Precisión sobre Velocidad
Debido a que la búsqueda vectorial es una aproximación de "vecinos más cercanos" diseñada para la velocidad, a menudo recupera fragmentos que son semánticamente similares pero legalmente irrelevantes. La solución es añadir una fase de Reranking.4 En este paso, se toman los mejores 20 o 50 fragmentos de la búsqueda inicial y se someten a un modelo de "Cross-Encoder". A diferencia de los embeddings, que comparan vectores pre-calculados, el reranker analiza el par (pregunta, fragmento) de forma conjunta, evaluando la relevancia real con una precisión mucho mayor.4 Aunque este proceso es más lento y costoso computacionalmente, es esencial en el derecho para garantizar que el fragmento utilizado para la generación sea exactamente el que contiene la norma aplicada.19
Comparativa de Almacenes de Vectores (Vectorstores)
Para un corpus jurídico de tamaño medio —típicamente entre 50,000 y 1,000,000 de fragmentos documentales— la elección de la base de datos vectorial determina no solo el rendimiento, sino también la viabilidad operativa y el cumplimiento de la privacidad de los datos.27
Criterio
ChromaDB
Pinecone
Weaviate
Naturaleza
Código abierto, local/embebido.
SaaS gestionado en la nube.
Código abierto, nube o local.
Búsqueda Híbrida
Soporte básico (creciente).
Disponible en tiers superiores.
Nativa y altamente configurable (BM25 + Vector).
Facilidad de Inicio
Extrema (3 líneas de código).
Alta (sin gestión de infra).
Media (requiere configuración de esquema).
Soberanía de Datos
Total (corre en tu máquina).
Limitada (datos en servidores de terceros).
Alta (permite despliegue on-premise).
Escalabilidad
Ideal para prototipos y <1M docs.
Escala a billones de vectores.
Muy alta, con soporte multi-tenancy.
Costo
Gratuito (solo costos de infra propia).
Pago por uso (puede ser costoso a escala).
Gratuito (self-hosted) o pago (Cloud).
Para la mayoría de los departamentos legales internos o firmas medianas que priorizan la privacidad, Weaviate se presenta como la opción más equilibrada por su capacidad de realizar búsquedas híbridas potentes y su flexibilidad para ser desplegado en infraestructuras controladas por la organización.27 ChromaDB sigue siendo el estándar de oro para el desarrollo rápido y herramientas de uso personal o de pequeña escala donde la simplicidad supera a la necesidad de escalabilidad horizontal.27
Integración Soberana: Ollama y el Despliegue de Modelos Locales
Uno de los mayores obstáculos para la adopción de la IA en el derecho es el riesgo de filtración de datos confidenciales y la pérdida del privilegio abogado-cliente al enviar información a nubes públicas como las de OpenAI o Anthropic.35 La aparición de Ollama ha cambiado este paradigma, permitiendo ejecutar modelos de lenguaje de vanguardia directamente en el hardware local de la firma.35
Ventajas de la Inferencia Local con Ollama
Ollama actúa como un motor de orquestación (similar a Docker para modelos de IA) que gestiona la carga de pesos, la aceleración por GPU y la exposición de una API compatible con los estándares de la industria.35 En un flujo de trabajo legal, el uso de Ollama garantiza:
Privacidad Total: Los documentos y las consultas nunca abandonan la red local de la oficina, permitiendo el procesamiento de información sensible, secretos comerciales o datos de procesos judiciales no públicos.35
Cumplimiento Normativo: Facilita el cumplimiento "por diseño" del RGPD y otras normativas de protección de datos, eliminando la necesidad de acuerdos complejos de procesamiento de datos con proveedores extranjeros.35
Independencia del Proveedor: La firma no está sujeta a cambios en los precios de las APIs, límites de tasa (rate limits) o la depreciación repentina de modelos comerciales.35
Modelos Especializados para Ollama: SaulLM y Llama 3.3
Aunque modelos generales como Llama 3 son capaces de realizar tareas legales, el uso de modelos adaptados al dominio ofrece una ventaja competitiva. La familia SaulLM (7B, 54B, 141B) ha sido entrenada específicamente en un corpus de más de 30 mil millones de tokens legales.41 Estos modelos demuestran una comprensión superior de la sintaxis y el razonamiento jurídico, siendo capaces de redactar cláusulas contractuales o resumir jurisprudencia con una precisión que los modelos generales solo alcanzan con prompts muy complejos.41 Para tareas de alta complejidad, se recomienda el uso de Llama 3.3 70B o SaulLM-54B/141B (modelos Mixture of Experts), que requieren hardware con al menos 48GB-80GB de VRAM para funcionar con fluidez.36
Modelo Recomendado
Tamaño
Hardware Mínimo
Caso de Uso Legal
SaulLM-7B-Instruct
7B
8GB RAM / GPU 8GB
Clasificación de documentos, resúmenes rápidos.
Mistral-7B / Llama-3-8B
8B
8GB RAM / GPU 8GB
Tareas generales de oficina, redacción de correos.
LFM2-8B / Qwen3-Coder
8B-30B
16GB-32GB RAM
Extracción de entidades, análisis de cláusulas.
Llama-3.3-70B / SaulLM-141B
70B-141B
64GB-128GB RAM / 2x RTX 4090
Razonamiento jurídico profundo, redacción de demandas.36
Métricas de Evaluación de la Calidad del RAG Jurídico
Evaluar un RAG jurídico es una tarea multidimensional. No basta con que la respuesta "suene bien"; debe ser correcta, estar basada exclusivamente en las fuentes proporcionadas y no omitir información crítica.32 El uso de métricas automáticas y el juicio humano experto son complementarios en este proceso.46
El Triángulo de Evaluación: Fidelidad, Relevancia y Precisión
Las métricas más utilizadas en la industria se agrupan en el framework de evaluación RAGas, que mide:
Faithfulness (Fidelidad): Mide cuántas de las afirmaciones hechas en la respuesta del LLM están realmente presentes en los fragmentos recuperados. Es la métrica clave para detectar alucinaciones.11
Answer Relevance: Evalúa si la respuesta generada realmente responde a la pregunta formulada por el usuario, evitando divagaciones.32
Context Precision / Recall: Mide si el sistema de recuperación fue capaz de encontrar todos los fragmentos necesarios para responder a la pregunta y si los colocó en los primeros puestos de la lista de resultados.11
Benchmarks Especializados: MLEB y Legal-DC
Más allá de las métricas de software, existen conjuntos de datos de prueba diseñados por expertos para estresar las capacidades de los sistemas RAG legales. El Massive Legal Embedding Benchmark (MLEB) se enfoca en la fase de recuperación, evaluando cómo los modelos de embedding manejan la jurisprudencia de múltiples jurisdicciones.22 Por otro lado, proyectos como Legal-DC y LegalBench-RAG proporcionan pares de pregunta-respuesta con referencias a nivel de cláusula, permitiendo una evaluación de "extremo a extremo" que imita el trabajo real de un abogado o un juez.20
Hallucinaciones: La Realidad de los Sistemas Actuales
Un estudio de la Universidad de Stanford en 2025 reveló que incluso las plataformas comerciales de élite (Lexis+ AI, Westlaw AI) presentan tasas de alucinación significativas, situándose entre el 17% y el 33% de las respuestas.13 Estas alucinaciones suelen ser "insidiosas", como citar una norma que existe pero aplicándola a una jurisdicción incorrecta o malinterpretando el sentido de un fallo judicial.13 Esto refuerza la idea de que los sistemas RAG son herramientas de asistencia, no sustitutos, y que la "trazabilidad" (la capacidad de ver la fuente original con un clic) es la característica de seguridad más importante del sistema.9
Casos de Uso Concretos de RAG en LegalTech
La aplicación de RAG ha pasado de ser una promesa tecnológica a una realidad operativa en diversas áreas de la práctica legal, con resultados medibles en eficiencia y precisión.49
vLex Vincent: Investigación y Análisis Global
Vincent AI es un ejemplo paradigmático de RAG a escala masiva. Conectado a una base de datos de más de mil millones de documentos, utiliza RAG para transformar preguntas en lenguaje natural en respuestas fundamentadas con citas autoritativas.52 Sus flujos de trabajo permiten "Analizar una Demanda", donde el sistema utiliza RAG para buscar precedentes que contradigan los argumentos de la parte contraria, logrando mejoras de productividad superiores al 38% en tareas de investigación.6
Harvey AI: La Plataforma para Grandes Firmas
Harvey ha diseñado una infraestructura RAG de grado empresarial que maneja tres tipos de datos: archivos temporales de chat, proyectos a largo plazo en "Vaults" y una biblioteca global de regulaciones.55 Su enfoque destaca por la aislamiento de datos, asegurando que el conocimiento generado para un cliente nunca se filtre a los procesos de otro, cumpliendo con los estándares de seguridad de las firmas más grandes del mundo.56
Luminance: Inteligencia en el Ciclo de Vida del Contrato
Luminance aplica RAG para convertir el repositorio de contratos de una empresa en una fuente de inteligencia activa. Su herramienta "Ask Lumi" permite a equipos de finanzas o ventas preguntar "¿qué derechos de uso de logotipo tenemos en los contratos de la región EMEA?", obteniendo respuestas instantáneas extraídas directamente de las cláusulas vigentes.48 Durante la negociación, Lumi utiliza RAG para comparar borradores con el "conocimiento institucional" de la firma, sugiriendo cambios basados en cómo se resolvieron negociaciones similares en el pasado.48
Lefebvre GenIA-L: Contexto Editorial y Administrativo
En el contexto europeo y español, GenIA-L de Lefebvre integra el RAG con sus bases de datos propietarias (Mementos, jurisprudencia y legislación). Su particularidad reside en el manejo de la Doctrina Administrativa, permitiendo a los abogados navegar por la complejidad de las resoluciones de organismos públicos con una guía asistida por IA que garantiza que la información esté siempre actualizada y verificada por un equipo editorial.60
Plataforma
Especialidad
Impacto Reportado
vLex Vincent
Investigación jurídica y análisis de litigios.
+38% en productividad de investigación.52
Harvey
Asistente integral para grandes firmas y consultoras.
Despliegue en 45 países con alta seguridad.56
Luminance
Gestión y negociación automatizada de contratos.
90% de ahorro de tiempo en revisión contractual.62
Lefebvre GenIA-L
Derecho español, fiscal y contable con base editorial.
Unificación de tareas legales en un solo chat seguro.61
Conclusiones y Futuro de la IA Jurídica Fundamentada
La investigación sobre el estado actual de los sistemas RAG aplicados al derecho permite concluir que nos encontramos ante una tecnología de madurez creciente, pero que requiere un rigor técnico extremo en su implementación. El pipeline RAG no es una solución de "instalar y olvidar"; su éxito depende de una optimización continua en cada una de sus fases.2
La Calidad del Dato es Suprema: El aforismo "basura entra, basura sale" cobra una relevancia crítica en el RAG jurídico. La inversión en modelos de embedding específicos para el dominio legal (como Kanon 2) y en estrategias de segmentación que respeten la lógica del documento (SAC, segmentación por cláusulas) es lo que distingue a una herramienta profesional de un juguete tecnológico.8
Soberanía como Requisito Ético: La posibilidad de ejecutar sistemas RAG completos de forma local mediante Ollama y modelos como SaulLM elimina las barreras éticas y de privacidad que antes frenaban la adopción de la IA en los despachos más conservadores. La soberanía de datos ya no es una opción, sino un estándar de facto para la práctica legal responsable.35
Trazabilidad sobre Generación: El valor real del RAG en LegalTech no reside en su capacidad para escribir oraciones fluidas, sino en su capacidad para actuar como un índice inteligente que conecta cada palabra con una fuente de autoridad verificable. La transparencia y la facilidad para que el humano audite la fuente son las métricas finales de éxito.9
Hacia Agentes Autónomos: El futuro inmediato apunta hacia el paso del RAG pasivo (que solo responde preguntas) a agentes de IA agentic que pueden ejecutar flujos de trabajo de varios pasos, como realizar una auditoría de debida diligencia completa, redactar una demanda y preparar un índice de pruebas, todo ello fundamentado en una recuperación de contexto masiva y precisa.50
En definitiva, RAG representa el puente necesario entre la potencia creativa de la inteligencia artificial y el rigor innegociable del mundo jurídico. Aquellas organizaciones que logren dominar las complejidades del chunking, la vectorización y la evaluación técnica de estos sistemas estarán a la vanguardia de una transformación histórica en la administración de justicia y el asesoramiento legal.
Fuentes citadas
Enhancing the Precision and Interpretability of Retrieval-Augmented Generation (RAG) in Legal Technology: A Survey - IEEE Xplore, acceso: mayo 9, 2026, https://ieeexplore.ieee.org/iel8/6287639/10820123/10921633.pdf
Improving RAG accuracy: 10 techniques that actually work - Redis, acceso: mayo 9, 2026, https://redis.io/blog/10-techniques-to-improve-rag-accuracy/
Towards Reliable Retrieval in RAG Systems for Large Legal Datasets - iris@unitn, acceso: mayo 9, 2026, https://iris.unitn.it/retrieve/19adfd83-1330-46c9-a19c-318641bdd2a0/2025.nllp-1.3.pdf
RAG techniques: From naive to advanced - Weights & Biases - Wandb, acceso: mayo 9, 2026, https://wandb.ai/site/articles/rag-techniques/
RAG in 2026: A Practical Blueprint for Retrieval-Augmented Generation - DEV Community, acceso: mayo 9, 2026, https://dev.to/suraj_khaitan_f893c243958/-rag-in-2026-a-practical-blueprint-for-retrieval-augmented-generation-16pp
Another New Study of Legal AI Shows Some Models Can Significantly Improve Work Quality and Efficiency | LawSites, acceso: mayo 9, 2026, https://www.lawnext.com/2025/03/another-new-study-of-legal-ai-shows-some-models-can-significantly-improve-work-quality-and-efficiency.html
Tutorial: Build Your Own RAG in 10 lines of Python - OpenMined, acceso: mayo 9, 2026, https://openmined.org/blog/tutorial-build-your-own-rag-in-10-lines-of-python/
Towards Reliable Retrieval in RAG Systems for Large Legal Datasets - arXiv, acceso: mayo 9, 2026, https://arxiv.org/html/2510.06999v1
Understanding the AI Models Used by Vincent | vLex Library Knowledge Base, acceso: mayo 9, 2026, https://support.vlex.com/vincent-by-vlex/vincent/security-privacy-and-compliance/understanding-the-ai-models-used-by-vincent
Open French Law RAG | Library Innovation Lab, acceso: mayo 9, 2026, https://lil.law.harvard.edu/open-french-law-rag/
Introducing Legal RAG Bench - Hugging Face, acceso: mayo 9, 2026, https://huggingface.co/blog/isaacus/legal-rag-bench
[2603.01710] Legal RAG Bench: an end-to-end benchmark for legal RAG - arXiv, acceso: mayo 9, 2026, https://arxiv.org/abs/2603.01710
Hallucination‐Free? Assessing the Reliability of ... - Daniel E. Ho, acceso: mayo 9, 2026, https://dho.stanford.edu/wp-content/uploads/Legal_RAG_Hallucinations.pdf
GitHub - Raudaschl/rag-fusion: RAG-Fusion: multi-query generation ..., acceso: mayo 9, 2026, https://github.com/Raudaschl/rag-fusion
Best Chunking Strategies for RAG Pipelines - Redis, acceso: mayo 9, 2026, https://redis.io/blog/chunking-strategy-rag-pipelines/
7 Chunking Strategies for RAG Systems (Examples) - F22 Labs, acceso: mayo 9, 2026, https://www.f22labs.com/blogs/7-chunking-strategies-in-rag-you-need-to-know/
Fixed-Size Chunking in RAG Pipelines: A Guide - newline, acceso: mayo 9, 2026, https://www.newline.co/@zaoyang/fixed-size-chunking-in-rag-pipelines-a-guide--af509f11
Best Chunking Strategies for RAG (and LLMs) in 2026 - Firecrawl, acceso: mayo 9, 2026, https://www.firecrawl.dev/blog/best-chunking-strategies-rag
8 Advanced RAG Techniques & How to Implement Them in Production - Intuz, acceso: mayo 9, 2026, https://www.intuz.com/blog/advanced-rag-techniques
Legal-DC: Benchmarking Retrieval-Augmented Generation ... - arXiv, acceso: mayo 9, 2026, https://arxiv.org/abs/2603.11772
Vector Database Comparison 2026: Pinecone vs Weaviate vs Milvus - Iternal AI, acceso: mayo 9, 2026, https://iternal.ai/blockify-vector-databases
Introducing Kanon 2 Embedder - Isaacus, acceso: mayo 9, 2026, https://isaacus.com/blog/introducing-kanon-2-embedder
AWS Marketplace: Kanon 2 Embedder - legal embedding model - Amazon.com, acceso: mayo 9, 2026, https://aws.amazon.com/marketplace/pp/prodview-qoz2rxyqhtewu
(PDF) The Massive Legal Embedding Benchmark (MLEB) - ResearchGate, acceso: mayo 9, 2026, https://www.researchgate.net/publication/396789828_The_Massive_Legal_Embedding_Benchmark_MLEB
Introducing the Massive Legal Embedding Benchmark (MLEB) - Hugging Face, acceso: mayo 9, 2026, https://huggingface.co/blog/isaacus/introducing-mleb
How I Built Lightning-Fast Vector Search for Legal Documents - Hugging Face, acceso: mayo 9, 2026, https://huggingface.co/blog/adlumal/lightning-fast-vector-search-for-legal-documents
Vector Databases Compared: Pinecone vs Weaviate vs Chroma - Propelius Technologies, acceso: mayo 9, 2026, https://propelius.ai/blogs/vector-databases-compared-pinecone-weaviate-chroma/
Metadata filtering in Vector databases | by Kandaanusha | Mar, 2026 | Medium, acceso: mayo 9, 2026, https://medium.com/@kandaanusha/metadata-filtering-in-vector-databases-e3ebe61c8f76
Advanced RAG — Improving retrieval using Hypothetical Document ..., acceso: mayo 9, 2026, https://medium.aiplanet.com/advanced-rag-improving-retrieval-using-hypothetical-document-embeddings-hyde-1421a8ec075a
5 Proven Query Translation Techniques To Boost Your RAG Performance, acceso: mayo 9, 2026, https://towardsdatascience.com/5-proven-query-translation-techniques-to-boost-your-rag-performance-47db12efe971/
Advanced RAG Techniques - Pinecone, acceso: mayo 9, 2026, https://www.pinecone.io/learn/advanced-rag-techniques/
EvaRAG: Evaluating Advanced RAG Techniques with Indexing and Distance Metrics, acceso: mayo 9, 2026, https://www.researchgate.net/publication/398972248_EvaRAG_Evaluating_Advanced_RAG_Techniques_with_Indexing_and_Distance_Metrics
RAG Vector Database Selection: Pinecone vs Weaviate vs ChromaDB for Developers, acceso: mayo 9, 2026, https://customgpt.ai/rag-vector-database-selection/
Choosing Your Vector Database: Pinecone vs. Weaviate vs. Chroma - Vatsal Shah, acceso: mayo 9, 2026, https://vatsalshah.in/blog/choosing-vector-database-pinecone-weaviate-chroma
Ollama: The Reference Architecture for Sovereign, Private Large Language Models (LLMs), acceso: mayo 9, 2026, https://ayedo.de/en/posts/ollama-die-referenz-architektur-fur-souverane-private-large-language-models-llms/
Local LLM Deployment: Privacy-First AI Complete Guide, acceso: mayo 9, 2026, https://www.digitalapplied.com/blog/local-llm-deployment-privacy-guide-2025
Run LLMs Locally with Ollama: Privacy-First AI for Developers in 2025 - Cohorte Projects, acceso: mayo 9, 2026, https://www.cohorte.co/blog/run-llms-locally-with-ollama-privacy-first-ai-for-developers-in-2025
How to Protect Sensitive Data by Running LLMs Locally with Ollama - freeCodeCamp, acceso: mayo 9, 2026, https://www.freecodecamp.org/news/protect-sensitive-data-with-local-llms/
Local LLM Hosting: Complete 2025 Guide — Ollama, vLLM, LocalAI, Jan, LM Studio & More, acceso: mayo 9, 2026, https://medium.com/@rosgluk/local-llm-hosting-complete-2025-guide-ollama-vllm-localai-jan-lm-studio-more-f98136ce7e4a
Why Your Local LLM is the Ultimate Privacy Power Move in 2026 | by Snehal Singh, acceso: mayo 9, 2026, https://medium.com/@snehal_singh/why-your-local-llm-is-the-ultimate-privacy-power-move-in-2026-8287859e1d06
Better Call Saul - SaulLM-7B - a legal large language model, acceso: mayo 9, 2026, https://training.continuumlabs.ai/continuum-applications/discussion-and-use-cases/better-call-saul-saullm-7b-a-legal-large-language-model
[2403.03883] SaulLM-7B: A pioneering Large Language Model for Law - arXiv, acceso: mayo 9, 2026, https://arxiv.org/abs/2403.03883
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain - arXiv, acceso: mayo 9, 2026, https://arxiv.org/html/2407.19584v1
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain - NIPS papers, acceso: mayo 9, 2026, https://proceedings.neurips.cc/paper_files/paper/2024/file/ea3f85a33f9ba072058e3df233cf6cca-Paper-Conference.pdf
Evaluación de LLMs: benchmarks clave para Large Language Models - Artificial Nerds, acceso: mayo 9, 2026, https://www.nerds.ai/blog/evaluacion-de-llms-principales-benchmarks-y-como-entenderlos
LLM-as-a-Judge: Rapid Evaluation of Legal Document Recommendation via Retrieval-Augmented Generation - EARL Workshop, acceso: mayo 9, 2026, https://earl-workshop.github.io/pdf/recsys2025-workshops_paper_4.pdf
LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain, acceso: mayo 9, 2026, https://www.semanticscholar.org/paper/LegalBench-RAG%3A-A-Benchmark-for-Retrieval-Augmented-Pipitone-Alami/3daedc1e0a9db8c4dda7e06724b0b556f64c0752
The Next Frontier for Contract Work : Legal-Grade™ AI That Understands the Bigger Picture, acceso: mayo 9, 2026, https://www.luminance.com/resources/blog/the-next-frontier-for-contract-work-legal-grade-ai-that-understands-the-bigger-picture/
Ten legal tech applications transforming law practice in 2025 | Leeds Beckett University, acceso: mayo 9, 2026, https://www.leedsbeckett.ac.uk/blogs/leeds-law-school/2025/07/ten-legal-tech-applications-transforming-law-practice-in-2025/
The 10 Legal Tech Trends that Defined 2025 | LawSites, acceso: mayo 9, 2026, https://www.lawnext.com/2026/01/the-10-legal-tech-trends-that-defined-2025.html
Ranking 2025: Las 8 Mejores AI Para Generación De Textos Legales - Darwin Blog, acceso: mayo 9, 2026, https://blog.getdarwin.ai/es/ranking-2025-las-8-mejores-ai-para-generaci%C3%B3n-de-textos-legales
Vincent AI - vLex, acceso: mayo 9, 2026, https://law.vlex.com/vincent
What is Vincent? | vLex Library Knowledge Base, acceso: mayo 9, 2026, https://support.vlex.com/vincent-by-vlex/vincent/getting-started-with-vincent/understanding-what-vincent-is
Practical AI for Litigators: Vincent is Closing Knowledge Gaps | TechLaw Crossroads, acceso: mayo 9, 2026, https://www.techlawcrossroads.com/2025/02/practical-ai-for-litigators-how-vincent-is-closing-knowledge-gaps/
Harvey | AI platform for legal and professional services, acceso: mayo 9, 2026, https://www.harvey.ai/
Harvey: Enterprise-Grade RAG Systems for Legal AI Platform - ZenML LLMOps Database, acceso: mayo 9, 2026, https://www.zenml.io/llmops-database/enterprise-grade-rag-systems-for-legal-ai-platform
Enterprise-Grade RAG Systems | Harvey, acceso: mayo 9, 2026, https://www.harvey.ai/blog/enterprise-grade-rag-systems
Gain Insight Into All Contracts Across the Enterprise - Luminance, acceso: mayo 9, 2026, https://www.luminance.com/analyze/
Legal AI That Acts the Way Lawyers Think - Luminance, acceso: mayo 9, 2026, https://www.luminance.com/resources/videos/legal-ai-that-acts-the-way-lawyers-think/
GenIA-L - Lefebvre Group, acceso: mayo 9, 2026, https://www.lefebvre-group.com/produits/genia-l/
Lefebvre presents in Spain the new AI features incorporated into GenIA-L that transform legal work, acceso: mayo 9, 2026, https://www.lefebvre-group.com/lefebvre-presents-in-spain-the-new-ai-features-incorporated-into-genia-l-that-transform-legal-work/
Legal Contract Management Software - Luminance, acceso: mayo 9, 2026, https://www.luminance.com/legal-contract-management-software/
How to Choose the Right Legal AI Platform for Your Team - Harvey, acceso: mayo 9, 2026, https://www.harvey.ai/blog/how-to-choose-best-legal-ai-platform